
Machine Learning and AI are transforming nearly every domain. Code is no different story. We all have seen the magical experience of using recently launched GitHub’s Copilot, which is more than a code completion system.
There has been a rise in interest in applying Machine Learning on Source Code to build tools to improve Developer Productivity. If we talk about some applications of Machine Learning on Source Code, it could simply be Vulnerability Detection, Code Translation, Code Summarization, Just in Time Defect Detection, and many more.
One challenge that remains is how do we represent source code in a form that effectively captures the syntax and semantics of source code. Every developer has their own style of writing code, choosing variable names, etc. Also, code is different from Natural Language in these terms. So, how do we deal with this? Well, we will try to answer these questions in this article.
Why Effective Code Representation is Important.
As with any other ML-related task, the better we capture the features of the data, the better modeling we would be able to perform. In order to capture both the syntax and semantics of source code, it is very important that we have some effective code representation techniques.
Code as Tokens
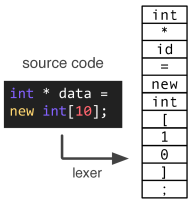
As a baseline, we can treat code simply as a stream of tokens as in any other Machine Learning task on Natural Language. While it is a good starting point, but we would soon realize that this may not be the most efficient way as every developer may use different names for variables and we discard any relationship between various code components as we know modern code is highly related, dependent and modular and it is, therefore, important to capture these relations.
Tokens may be further seen as keywords, identifiers, literals, operators, etc for further drilled down structure.
Code as Normalised Tokens

Normalised Source Code Tokens.
While it was great to start with representing code as a plain sequence of tokens, we may want to apply some sort of normalisation on top of it, so that tokens generalise well with any downstream machine learning task.
To normalise, we simply replace few tokens with their abstract representation forms. For eg, we may not need strings in code to model source code (strings may also contain secret information, therefore it is best to encode them), therefore we can replace all strings with “STRING”; Similarly, all assignment operators can be replaced with “ASSIGN”. All functions/class names can also be replaced. All variable names can be replaced with “VAR” etc.
This way we mask these tokens and make it more generalised to see improvements in our modeled source code.
Why Graph for Code?
Graphs structures are a natural representation of many kinds of data. They are a good way to represent relationships between objects. Objects can be represented by Node of Graph and they can have some associated properties. Similarly, the relation between those objects can be represented as Edges in a graph, where each edge can have its own type. Edges can be directed, and each edge can have a value, such as a label or a number associated with it to represent the nature of the edge. Using graph structures, we can represent complex relationships and interactions between different objects.
Graphical Data Structure captures the relationship in code such as Syntax Dependency, Control Flow, Last Used, Last Modified, Computed From, etc.
If you are interested to learn more about Machine Learning on Graphs, I would recommend this course from Stanford University.
Code as Graph
Representing Code as Graph has been heavily used in Compilers and IDEs for various tasks. Using the graphical structure of code to present it to any Graph ML algorithms creates SOTA results.
Abstract Syntax Tress (AST)
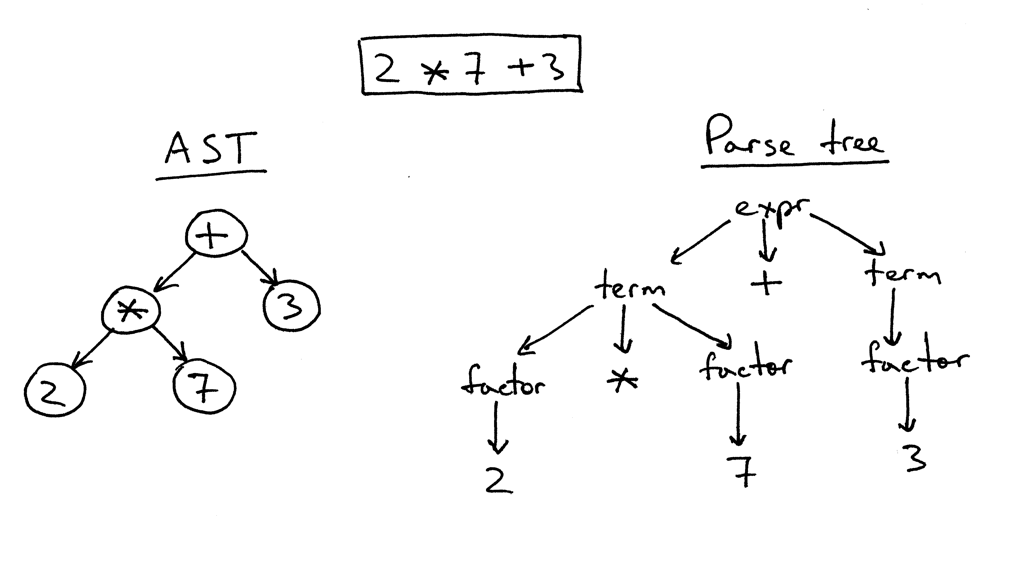
Tree Representation of Code Statement: 2*7 + 3
Relationships in code can be represented in graphs. For instance, Abstract Syntax Trees (ASTs) are graphs that represent the syntactic structure of program code. This graph translates the program code into a graph structure while preserving individual elements of its syntax.
Control Flow Graph (CFG)
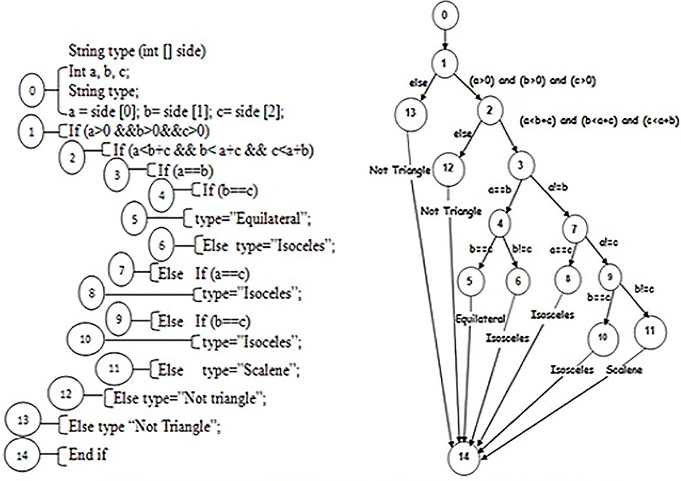
Control Flow Graph
Control Flow Graphs (CFGs) are designed to represent the order in which code is executed and conditions that need to be met for that piece of code to be executed. In a CFG, each node represents instructions of the program while edges represent the flow of control in the program. With CFGs, we can traverse the graph to determine which instructions can be called at various points during the execution.
Program Dependence Graph (PDG)

Program Dependency Graph
PDGs represent data and control dependencies of a piece of code. In a PDG, data dependency edges specify the influence of a piece of data, and control dependency edges specify the influence of predicates on other nodes. In this context, predicates are logical expressions that evaluate TRUE or FALSE used to direct the execution path. Using PDGs, we can see how data travels through the code and if a particular piece of data can reach a specific statement.
Which Graph Representation of Code is Best?
Different graph representations of code are optimised for different purposes and used by security experts to examine specific code components specifically for security analysis.
The real power of the graph representation of code can be harnessed when we combine the different representations into one common graphical structure. The AST, CFG, and PDG all represent the same code from a different perspective, and some properties of the program are easier to express in one representation over the other. Combining these graphs representing different properties of a program allows us to construct a master graph that merges the different perspectives and takes them all into account.
Several attempts have been made to effectively capture all this information into the common graphical structure. One of the most common ones is Code Property Graph or CPG by Fabian Yamaguchi.
Code Property Graph (CPG)
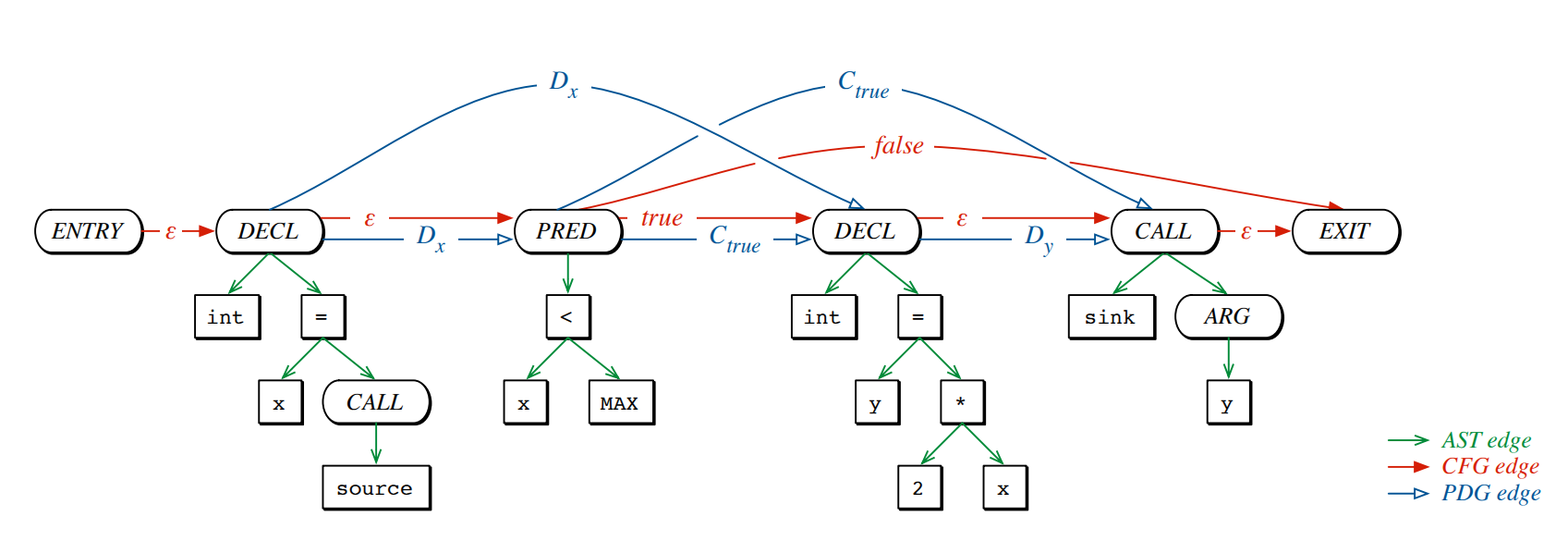
Code Property Graph has all three edges of AST, CFG and PDG
Code Property Graph merges the concepts of classic program analysis, namely abstract syntax trees, control flow graphs, and program dependence graphs, into a joint data structure. This comprehensive representation enables anyone to elegantly model templates for common vulnerabilities with graph traversals that, for instance, can identify buffer overflows, integer overflows, format string vulnerabilities, or memory disclosures, etc.
Joern is an open-source tool that utilises the CPG to conduct source code analysis.
Such representation helps to query the source code and can also be utilised to use as Input to Graph Neural Networks to classify for instance vulnerable and non-vulnerable code or to learn malicious control flows information patterns.
We at Embold extensively use these above representations to model source code effectively for generating the best possible models that are used to build tools to improve developer’s productivity.
Comments are closed.