
Introduction
PostgreSQL is an open-source relational database programming language used worldwide. It is an extended subset of SQL and includes foreign keys, sub-queries, triggers, user-defined types, and functions. Complex data structures can be created, stored, and retrieved.
PostgreSQL is scaling up language and handles most of the complicated data. Though it is free and updated continuously with a lot of fixes, it has a huge global community backing up.
Benefits of Postgres
Embold supports PostgreSQL 9.6 version and soon it will be migrated to the higher version.
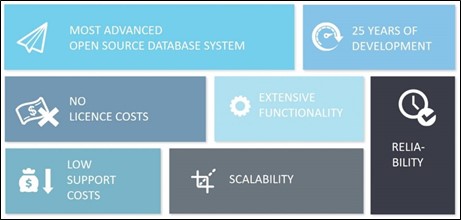
Why Choose PostgreSQL?
- Open source -> Source code is freely available under an open-source license. This allows you the freedom to use, modify and implement it as per your business needs.
- Reduce costs -> As a true open-source product, PostgreSQL does not cost anything- No license fees.
- Performance -> Handle enterprise workloads, performance improvement in the last 4 years.
- Extensibility ->Supported by a wide array of extensions plus multiple SQL and NoSQL data models.
- Built for speed -> Broadly availability makes it straightforward to install and test.
- Community driven -> Multiple companies and individuals contribute to the project and drive innovation.
- Scalability -> Multiple technical options for operating PostgreSQL at scale.
- Security -> There are many features for enhanced security, thanks to easy extensibility: however, if you make use of the right ones, you get a very secure database, which takes care of your most valuable asset.
- Saving high license costs -> migrating to PostgreSQL
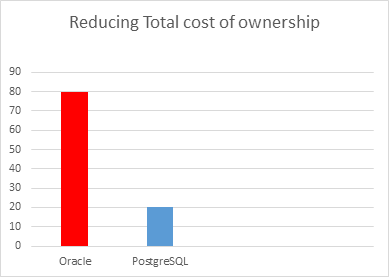
By migrating to PostgreSQL, companies can reduce the total cost of ownership up to 75-80%.
Key Features
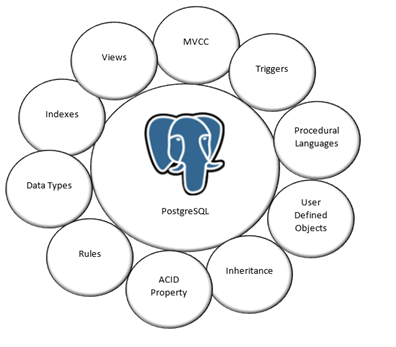
- Procedural languages: PostgreSQL supports procedural languages. These procedural languages allow a user to write their code and database server to execute that code. PL/Python, PL/pgSQL, PL/Tcl, PL/Perl are procedure languages supported by PostgreSQL. PostgreSQL also supports non-standard procedural languages such as PL/Ruby, PL/Java, PL/PHP but all of them need to be installed in some additional packages.
- Indexes: PostgreSQL allows the user to create their customized indexes. It supports hash, B+ tree, generalized search tree, etc.
- Triggers: Triggers are initialized by DML commands like insert, update, and those are fully supported by PostgreSQL.
- Views: Views are virtual tables and they produce based on the result set. Views are supported by PostgreSQL.
- MVCC: PostgreSQL allows many users (Readers, Writers) to work on a database at the same time rather than enforce the Read-Write Lock policy. It happens because of Multiversion Concurrency Control (MVCC). MVCC uses “snapshots” to represent the state of the database at a specific moment. Users are not able to see the other user transactions until they get committed and achieve the concurrency. In the case of reading operations, the reader sees only the current committed state of a database. MVCC puts safeguards in some places to ensure that multiple writers trying to modify the same data or row and that do not run into problems.
- Rules: PostgreSQL supports rules. Rules allow the hierarchy of incoming queries to be re-written.
- Data Types: PostgreSQL supports a wide range of data types such as text, char, varchar, Boolean, date/time, binary, variable-length array, and many more. PostgreSQL supports a custom data type that means it allows the user to create a new data type. For example, a user can combine a column labeled ‘name’ of string type and another column labeled ‘salary’ of numeric type and result in this new composite type ‘employee’.
- User-defined objects: PostgreSQL supports the creation of new objects present inside the database like tables, indexes, views, domains, functions, etc.
- Inheritance: In PostgreSQL, the table can inherit characteristics from the parent table and set them to it. As in table inheritance, the child table inherits properties of the parent and adds their properties, in this way user able to create a much more complex data structure in a purely relational database. This can be a huge advantage if your application produces data, which do not fit into a relational database that time PostgreSQL help you out.
- ACID Property: PostgreSQL is ACID (Atomicity, Consistency, Isolation, and Durability) compliant by default.
Database PostgreSQL query:
json_populate_recordset: This function is used for the conversion of JSON to the table format.
sample JSON: studentdata
[ {
"id": "1",
"name": "Ross",
"birthyear": "1980",
"created_date": "2021-06-25 09:19:10",
"updated_date": "2021-06-25 09:19:10",
},
{
"id": "2",
"name": "Rachel",
"birthyear": "1983",
"created_date": "2021-06-25 09:19:10",
"updated_date": "2021-06-25 09:19:10",
}
]Database Query:
create temp table student_table
(“Id” int,”Name” varchar, “Birthyear” int,”Created_date” timestamp with time zone,”Updated_date” timestamp with time zone);
insert into student_table SELECT * FROM
json_populate_recordset(NULL::student_table, studentdata::json);Output:
| Id | Name | Birthyear | Created_date | Updated_date |
| 1 | Ross | 1980 | 2021-06-25 09:19:10 | 2021-06-25 09:19:10 |
An explanation for the above example
The function “json_populate_recordset” converts JSON array values into SQL records. Input is the JSON, and output is in the form of a table.
The values in the query are populated from the JSON file.
Here, NULL:type_identifier is the first formal parameter and null is a default value to insert into table columns and not set in JSON passed (in above e.g: NULL::student_table) and JSON value is passed by a second formal parameter (in above e.g. studentdata::json).
Conclusion
Overall, PostgreSQL accelerates complex queries into simpler ones; typically used for creating web application development.
Embold supports JSON and JSONB formats for easy readability and to update queries quickly.
How have you implemented PostgreSQL in your product? Feel free to comment below.
Comments are closed.